HoG & SVM
In the field of object detection in computer vision, the use of robust and well-structured pipelines is essential to ensure reliable results, especially in resource-constrained environments. The HOG-SVM object detection pipeline I developed integrates the Histogram of Oriented Gradients (HOG) method as a feature extractor and Support Vector Machines (SVM) as the classifier. This system is designed to offer an efficient and accessible solution for prototyping, training, and validating object detection models using the Dlib library.
This pipeline provides a powerful alternative for those looking to implement detection systems without the need for a GPU, while still achieving solid results from limited datasets.
Table of Contents
- Motivation
- What is HOG+SVM?
- Pipeline Structure
- Requirements
- Usage Instructions
5.1. Resizing Images
5.2. Labeling Images
5.3. Training the Model
5.4. Validating the Model
5.5. Testing with Pre-trained Model - Advantages and Disadvantages
- License
Motivation
This project was motivated by the desire to return to a simpler neural network architecture, specifically using a classifier, to address a basic object identification problem.
In the provided example, the goal is to detect a single class—such as a red ball—where deploying a computationally expensive model like a Convolutional Neural Network (CNN), nowadays very popular, requiring a GPU would be disproportionate.
At the same time, traditional image processing techniques (e.g., dilation, erosion, edge detection) tend to be too sensitive to environmental variations, such as lighting changes, and thus lack generalization.
The HOG-SVM pipeline offers a lightweight yet effective solution for simple object detection tasks, striking a balance between computational efficiency and robustness in varying conditions.
What is HOG+SVM?
HOG (Histogram of Oriented Gradients) is a feature extraction method that describes the structure and appearance of an object by analyzing gradient orientations in localized portions of an image. It's widely used in object detection, especially for its robustness to variations in lighting and pose.
SVM (Support Vector Machine) is a supervised machine learning algorithm that classifies data by finding the hyperplane that best separates the feature space into categories.
In the context of object detection, HOG features are extracted from the images and fed into an SVM for training. The trained SVM can then be used to classify objects in new images.
For a visual understanding of the HOG+SVM process:

Pipeline Structure
object_detection_HOG-SVM_pipeline
├── assets
├── images
│ ├── resizer.py
│ ├── test
│ ├── train
│ └── validation
├── README.md
├── resources
│ ├── ball_recognition_exemple.svm
│ ├── test_label.xml
│ └── train_label.xml
└── scripts
├── detector4images.py
├── detector4webcam.py
└── train.py
Requirements
Before running the pipeline, ensure that you have the following Python libraries installed:
- Dlib (for object detection and training)
- OpenCV (for image processing and webcam access)
- NumPy (for numerical computations)
To install these dependencies, run the following command:
pip install dlib opencv-python numpy
Additionally, make sure you have a C++ compiler installed to build Dlib, as it requires compilation. On Ubuntu, you can install the necessary packages with:
sudo apt-get install build-essential cmake
sudo apt-get install libgtk-3-dev libboost-all-dev
Once these are installed, you should be ready to run the pipeline.
Usage Instructions
1. Resizing Images
To begin, you must resize the training, test, and validation images based on your desired detection frequency. The resizing script adjusts the image resolution to achieve a balance between frequency and resolution, as shown in this graph:
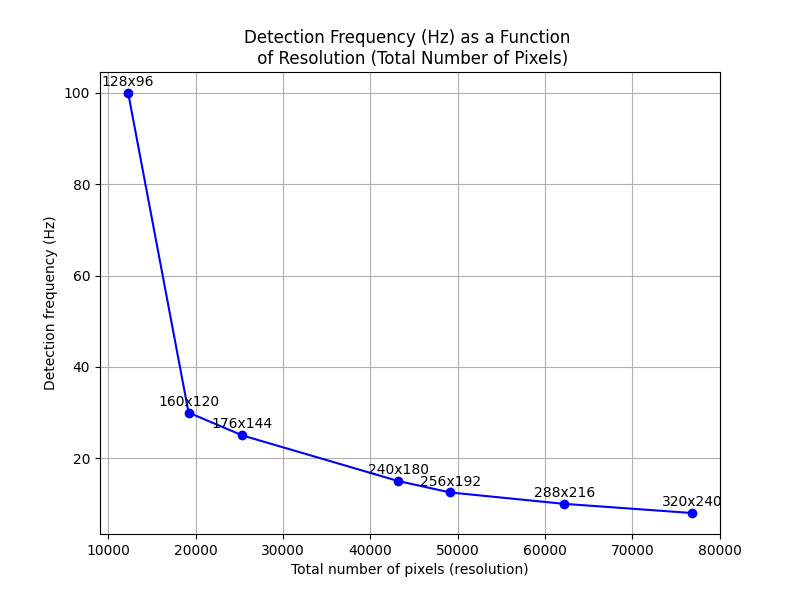
By default, the frequency is set to 10Hz for an image resolution of 288x216px.
Run the following command in the images directory:
python resizer.py
2. Labeling Images
To generate the XML label files for Dlib, you can use the Imglab labeling tool. Once the labeling is done, save the files in Dlib's XML format. Place the generated label files in the resources folder.
The sample label files for training and testing are already provided (train_label.xml and test_label.xml).
3. Training the Model
Before training, ensure that the paths to the images are correctly set in the XML label files. Once confirmed, execute the training script:
python train.py
This script uses Dlib to train an object detector based on the labeled data. You can customize the hyperparameters of the training process by referring to the Dlib documentation: Dlib Object Detector Training Options.
4. Validating the Model
To validate the trained model on test images, execute the following command:
python detector4images.py
The script will output the results of the model's performance on the test images.
5. Testing with Pre-trained Model
If you want to test the pipeline using a pre-trained model, a trained SVM model on 100 images is provided (ball_recognition_exemple.svm). You can test it on your webcam by running:
python detector4webcam.py
An example of the webcam output:

Advantages and Disadvantages
| Advantages | Disadvantages |
|---|---|
| Works without a GPU | Requires a minimum image size |
| Small dataset is sufficient for good results (5 images here) | Minimum object size (400px²) required for detection |
| High frequency achievable with small image sizes | Small objects in the image may not be detectable due to lack of detail |
By following this pipeline, you can quickly train and test object detection models using HOG+SVM, even with limited computational resources.
License
This project is licensed under the BSD 3-Clause License.